


Ezhilvendan Selvam
April 21, 2025
10 Minutes read
Synthetic Data for AI Model Training: Leveraging Cloud to Solve Data Privacy Challenges
In today’s data-driven world, AI models require vast amounts of data to improve accuracy and predict outcomes. However, using real-world data can present significant privacy challenges, especially when dealing with sensitive information. This is where synthetic data can offer a revolutionary solution. By generating realistic data without compromising privacy, organizations can train AI models efficiently. Cloud technologies, known for their scalability and flexibility, make synthetic data generation more accessible than ever. In this blog, we explore the benefits, challenges, cloud support, and practical applications of synthetic data, with a special focus on sectors like healthcare, finance, and smart cities.
What is Synthetic Data?
Synthetic data is artificially generated data designed to simulate real-world data patterns and statistical distributions without involving any real user information. This approach allows companies to build and train AI models while maintaining privacy and security, ensuring compliance with stringent data protection laws such as GDPR, HIPAA, and CCPA. Explore our blog to learn more about synthetic data and its transformative impact.
Key Benefits of Synthetic Data
- Privacy Preservation: No real identities or sensitive information are included.
Example: Hospitals can simulate patient data for conditions like diabetes or heart disease without using real records. - Regulatory Compliance: Ensures adherence to global standards like GDPR, HIPAA, and CCPA.
Example: Enterprises can train models using GDPR-compliant synthetic datasets instead of risking customer data exposure. - Data Augmentation: Enhances limited datasets for more accurate and diverse AI models.
Example: Generating synthetic traffic data to train self-driving vehicle models in rare or dangerous scenarios. - Cost-Efficiency: Reduces the need for expensive real-world data collection and cleaning.
Example: Replacing manual data collection in financial transactions with synthetic alternatives for fraud detection.
Challenges in Using Synthetic Data for AI Model Training
While synthetic data is powerful, organizations must address several key challenges to ensure its effectiveness in training AI models:
- Data Realism and Quality: Synthetic data must accurately represent complex, real-world patterns. Oversimplified datasets can lead to underperforming models in real-world applications.
Example: A chatbot trained on generic patient data may struggle to recognize rare disease symptoms in actual healthcare settings. - Bias Propagation: If the original dataset has bias, the synthetic version might replicate or worsen it, compromising model fairness.
Example: An AI model trained on historical loan data may continue to overlook low-income applicants if the synthetic data inherits those biases. - Validation Difficulties: Without a definitive “ground truth,” validating the accuracy and utility of synthetic data is complex. Statistical similarity tests may not reliably predict real-world model performance.
- Requires Specialized Tools and Skills: Effective synthetic data generation requires specific knowledge, privacy expertise, and advanced AI modeling skills resources, which many teams may lack.
- Privacy is Not Absolute: If not handled correctly, synthetic data could still leak patterns from the original dataset, leading to re-identification and compliance risks.
- Integration Challenges with Real Data Pipelines: Merging synthetic data and real-world data systems demands robust governance, including schema alignment, data lineage, and audit readiness.
ACL Digital’s Approach to Mitigating Synthetic Data Challenges
ACL Digital takes a structured, best-practice-driven approach to address the complexities of using synthetic data for AI model training. Our methodology focuses on ensuring data quality, fairness, privacy, and seamless integration:
- Rigorous validation using statistical techniques and domain expert feedback
- Embedded bias detection and fairness modeling to ensure ethical outcomes
- Implementation of privacy-by-design frameworks to safeguard data integrity
- Cloud-native, real-time integration support for seamless pipeline compatibility
Synthetic Data Techniques for AI Model Training
To effectively use synthetic data in AI model training, several techniques are commonly adopted depending on the data type and specific use case:
- Generative Adversarial Networks (GANs): GANs are deep learning models that learn from real datasets to generate new, realistic samples. They are widely used in domains such as computer vision, speech synthesis, and text generation.
- Agent-Based Simulation: These simulations model environments with multiple interacting agents, making them ideal for complex scenarios like traffic systems, robotics, and smart city planning.
- Rule-Based Data Generation: Uses predefined rules and statistical logic to generate synthetic datasets, particularly useful in structured domains like finance, healthcare, and retail.
- 3D Simulation and Sensor Emulation: Used primarily in autonomous systems, synthetic environments simulate sensor input (like LiDAR, radar, and camera data) for safe and scalable model training.
These methods can be seamlessly integrated into training pipelines using cloud-native tools like AWS SageMaker, Azure Machine Learning, and Google Vertex AI, enabling scalable and privacy-compliant AI development.
How Cloud Platforms Accelerate Synthetic Data Generation
Cloud platforms such as AWS, Microsoft Azure, and Google Cloud offer scalable, cost-effective, and secure infrastructure for synthetic data generation. These platforms provide high-performing computing resources like GPUs and TPUs, making it easier to generate large volumes of synthetic data on a scale. Additionally, they offer a range of tools that can automate the process, further simplifying synthetic data creation.
- Amazon Web Services (AWS)
- Amazon SageMaker Ground Truth: Supports synthetic data generation capabilities for labeling and training AI models using 3D simulation environments.
- AWS SimSpace Weaver: Helps generate large-scale synthetic environments for agent-based simulations.
- AWS Partner Network Tools: Platforms like Mostly AI and Hazy are often deployed on AWS for synthetic data use cases.
- Microsoft Azure:
- Azure Machine Learning + Unity Perception Toolkit: Facilitates synthetic image generation for computer vision applications.
- Azure Data Factory: While not designed specifically for synthetic data, it can orchestrate complex data pipelines that include synthetic data workflows.
- Third-Party Integration: Tools like Tonic.ai and Synthesized.io are often deployed on Azure for use in industries such as finance and healthcare.
- Google Cloud Platform (GCP)
- Vertex AI with DeepMind’s Generative Models: Enables advanced synthetic data generation for model training.
- Dataflow & Simulations: Custom synthetic pipelines can be built using Google Dataflow and BigQuery ML.
- Gretel.ai Integration: Gretel runs seamlessly on GCP, providing scalable, privacy-preserving synthetic data solutions.
Advantages of Using the Cloud for Synthetic Data
- Scalability: Easily manage large datasets and complex synthetic data generation tasks as your needs grow.
- Flexibility: Leverage a wide range of data generation models tailored to specific use cases and domains.
- Cost-Effectiveness: Cloud platforms provide a pay-as-you-go pricing model that minimizes upfront infrastructure costs.
- Security: With robust security measures, cloud platforms ensure both real and synthetic data are protected from unauthorized access and breaches.
Generic Architecture for Synthetic Data in AI Model Training
To generate and leverage synthetic data at scale, a well-architected, cloud-native pipeline is essential. The architecture below presents a vendor-neutral framework adopted across industries like healthcare, finance, and automotive for training AI models with synthetic data.
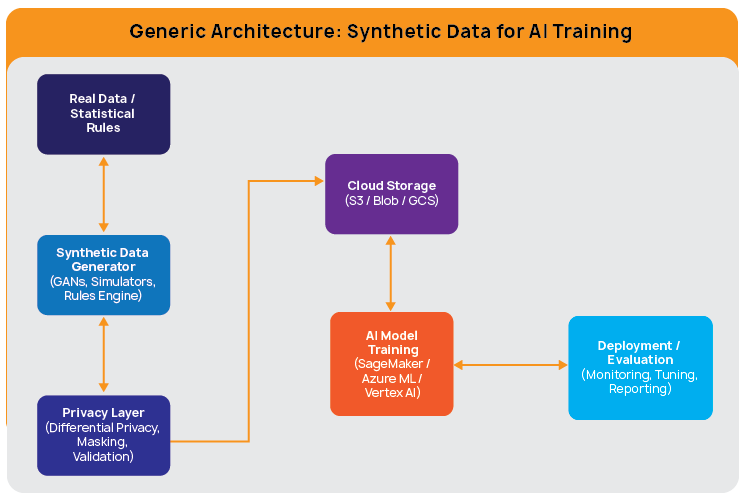
- Input Layer: Real Data or Simulation Rules: The process often starts with sample data, simulation rules, or domain-specific knowledge. These are used to inform how the synthetic data will be generated.
Example: Defining rules to simulate hospital admission patterns or e-commerce transaction flows. - Synthetic Data Generator Engine: At the core, this engine uses techniques like GANs, agent-based simulations, or rule-based logic to create artificial datasets that replicate the original data’s structure and behavior.
Popular Tools: Gretel.ai, Mostly AI, Tonic.ai, MDClone, Hazy - Privacy & Validation Layer: Before data is used, privacy-preserving techniques like differential privacy, data masking, or distribution matching are applied to ensure regulatory compliance such as HIPAA or GDPR. Statistical tests are run to validate data quality and fidelity.
Common methods: k-anonymity, JS divergence, re-identification risk scoring - Cloud Storage Layer: Synthetic data is securely stored in cloud object storage systems, optimized for access by training systems. Security features like encryption, role-based access control (RBAC), and versioning are enabled here.
Cloud Services: Amazon S3, Azure Blob Storage, Google Cloud Storage - AI/ML Model Training Environment: Models are trained on synthetic data within the same cloud environment. Platforms like SageMaker, Azure ML, or Vertex AI support model development, tuning, and evaluation.
Supported use cases: NLP models, fraud detection, medical imaging, demand forecasting - Evaluation, Monitoring, and Deployment: After training, models are evaluated against test datasets and monitored using tools like MLflow, CloudWatch, or Grafana. Deployment is carried out via APIs or integrated MLOps pipelines.
Outputs: Predictive models, embedded decision systems, operational dashboards
Use Case 1: Healthcare – Simulating Patient Data for Medical Research
The Challenge
In healthcare, patient data is highly sensitive and subject to strict privacy regulations like HIPAA. Access to real patient data for AI model training is restricted, making it difficult to develop accurate predictive models.
The Solution
Cloud-based synthetic data generation enables the creation of realistic, anonymized patient records that reflect clinical patterns. This allows researchers to train AI models without violating privacy laws.
Real-World Application
A hospital can use cloud platforms to generate synthetic datasets for chronic conditions like diabetes or cardiovascular disease. These datasets allow AI models to predict patient outcomes and personalize treatment plans, improving healthcare delivery while complying with regulations.
ACL Digital Experience
ACL Digital has partnered with leading healthcare providers to implement cloud-native synthetic data solutions, enabling safe and compliant model training. From HIPAA-compliant chatbot integrations to generating disease-specific synthetic datasets, our team ensures AI innovation without compromising patient confidentiality.
Market-Ready AI Solutions
- MDClone: Enables healthcare institutions to generate synthetic medical data for research.
- Syntegra: Provides synthetic patient records to support medical AI models.
Use Case 2: Financial Services – Fraud Detection and Risk Assessment
The Challenge
Financial institutions must comply with strict data privacy standards, restricting the use of sensitive transaction data for AI model training. Fraud detection systems require access to vast and diverse datasets that often include personally identifiable information (PII).
The Solution
Cloud-based synthetic data generation enables the creation of artificial transaction datasets that simulate real-world fraud and legitimate transactions. These datasets can be used to train fraud detection algorithms effectively, without exposing sensitive financial data.
Real-World Application
A financial institution can use synthetic transaction datasets that mimic customer spending patterns, helping AI models to detect fraudulent activities. These AI systems can identify suspicious behavior, protect customer assets, and maintain regulatory compliance.
ACL Digital Experience
ACL Digital has supported financial institutions in developing synthetic transaction data environments on AWS and Azure, enabling real-time fraud detection systems. We’ve helped banks simulate high-volume, diverse transaction flows to enhance the accuracy of ML models while ensuring full regulatory compliance.
Market-Ready AI Solutions
- Mostly AI: Generates synthetic financial transaction data for AI fraud detection models.
- Hazy: Provides compliant synthetic data solutions tailored for financial services.
Use Case 3: Smart City Planning – Privacy in Public Data for Urban Development
The Challenge
Smart cities rely on data from traffic sensors, public transport systems, and IoT devices to optimize urban infrastructure. However, collecting and using real-time data can pose privacy risks, particularly in densely populated areas where personal information could be exposed.
The Solution
Synthetic data platforms can simulate real-time urban data such as traffic patterns, public transport usage, and energy consumption. Cloud platforms can generate this data on demand, enabling AI models for urban planning, traffic management, and energy optimization while preserving the privacy of citizens.
Real-World Application
A city can generate synthetic datasets reflecting traffic patterns and public transport usage. AI models trained on this data can optimize traffic signals, reduce congestion, and improve overall transportation efficiency, making the city smarter and more livable.
ACL Digital’s Experience
ACL Digital has worked with urban development agencies and smart city innovators to implement IoT-powered synthetic data simulations. By leveraging Azure and Google Cloud, we’ve helped cities model traffic, optimize infrastructure, and drive data-driven governance, all while ensuring data anonymity.
Market-Ready AI Solutions
- DataRobot: Enables synthetic data-driven AI models for city planning.
- Tonic.ai: Specializes in generating synthetic data for urban development projects.
Explore More: Real-World Case Studies
Interested in how these innovations look in action? Here are two real-world implementations by ACL Digital that demonstrate the impact of Digital Twin in healthcare solutions:
Gain strategic insights into how Digital Twin technology is reshaping healthcare diagnostics, monitoring, and personalized care.
Key Takeaways
- Synthetic data helps AI systems train faster, cheaper, and more securely.
- Cloud providers simplify and scale data generation for AI use cases.
- ACL Digital delivers solutions that are secure, bias-aware, and compliant.
- Industries from healthcare and finance to urban infrastructure are already benefitting.
Conclusion: Cloud IoT Services and Synthetic Data for the Future
Synthetic data, when combined with cloud-based IoT services, provides an ideal solution for organizations to train AI models while overcoming privacy and data access challenges. Whether it’s enhancing medical diagnostics, detecting financial fraud, or optimizing urban infrastructure, synthetic data enables the development of intelligent systems without exposing sensitive information or breaching regulatory compliance.
By leveraging cloud platforms for synthetic data generation, organizations can ensure global privacy law compliance while gaining scalable, cost-effective, and secure environments for AI innovation. As the demand for data-driven solutions continues to grow, synthetic data capabilities in the cloud will become a critical differentiator for enterprises delivering AI and IoT-powered services.
About ACL Digital
At ACL Digital, we specialize in building and deploying AI-driven chatbots tailored to address the unique needs of the healthcare industry. As experts in cloud services, we help healthcare providers integrate intelligent chatbot solutions that enhance patient care, streamline operations, and ensure compliance with HIPAA regulations.
Our expertise extends beyond chatbots. We leverage cloud and AI-driven solutions to help organizations harness the power of synthetic data while ensuring scalability, security, and adherence to regulatory standards. With deep expertise in leading cloud platforms such as AWS, Azure, and Google Cloud, we develop robust AI models tailored to industries including healthcare, finance, and smart cities.
With our proficiency in AI model training and cloud-based synthetic data generation, we empower businesses to accelerate innovation while maintaining strict data privacy standards. By integrating scalable cloud solutions with advanced AI techniques, we help enterprises enhance fraud detection, optimize smart city planning, and improve medical research, without compromising sensitive data.
Connect with our experts to learn how we can support your AI and cloud initiatives.
Related Insights


Why AI-Powered Marketing Is Key to Business Growth
Tharik Mohamed Alikul Jaman


How multimodal interactions enhance the experience of commerce
Balasubramanian